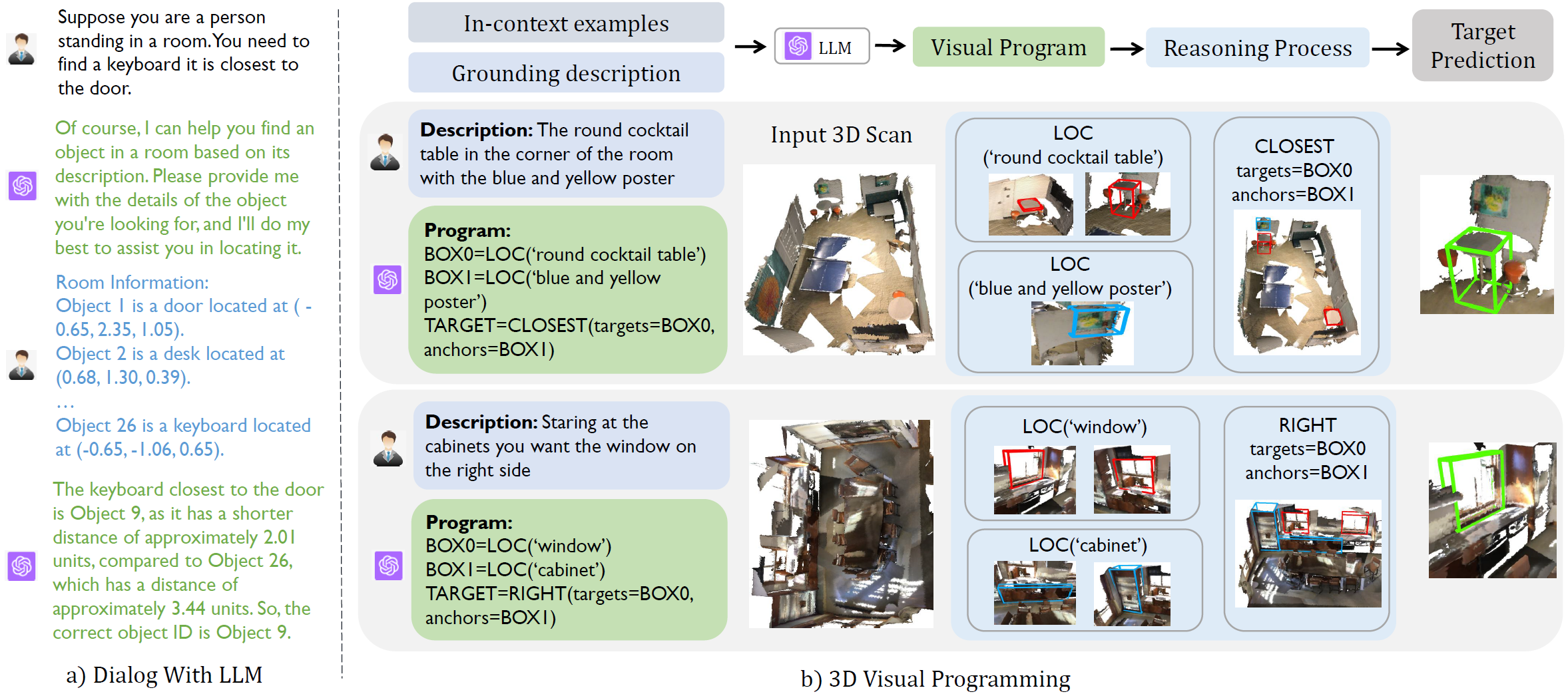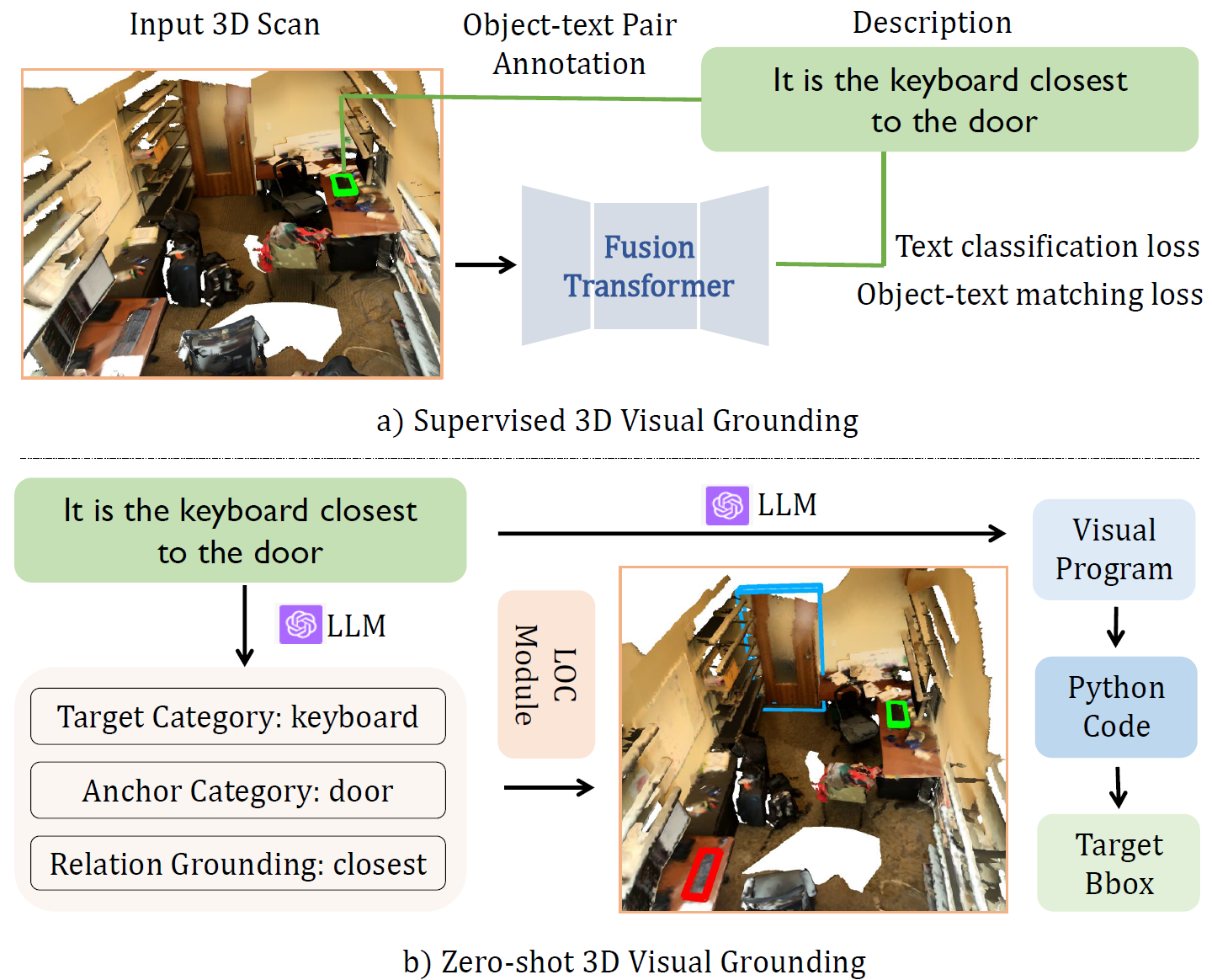
Comparative overview of two 3DVG approaches.
(a) Supervised 3DVG involves input from 3D scans combined with text queries, guided by object-text pair annotations, (b) Zero-shot 3DVG identifies the location of target objects using programmatic representation generated by LLMs, i.e., target category, anchor category, and relation grounding, thereby highlighting its superiority in decoding spatial relations and object identifiers within a given space, e.g., the location of the keyboard (outlined in green) can be retrieved based on the distance between the keyboard and the door (outlined in blue).